DNA als Super-Datenspeicher
1972 gelang es Forschern, die Desoxyribonukleinsäure (DNA) mit den vier relevanten Bausteinen (Adenin, Thymin, Guanin und Cytosin, abgekürzt: A, T, G und C) künstlich zu synthetisieren. Forscher haben damit die Idee umgesetzt, die DNA als Datenspeicher mit den Basen A, T, G und C als Code ähnlich wie beim maschinenlesbaren Strichcode zu verwenden. Statt des Binärsystems aus den Zahlen Null und Eins wird hier ein Quartärnärsystem benutzt, wobei der Genbaustein A der Zahl 0 (binär 00), T der Zahl 1 (binär 01), C der Zahl 2 (binär 10) und G der Zahl 3 (binär 11) entspricht.
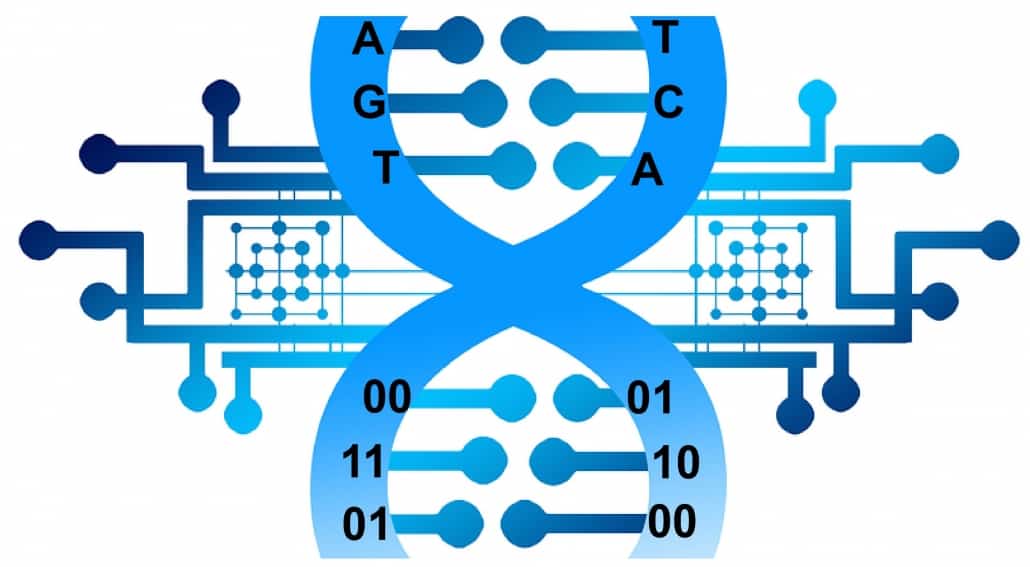
Gentechnik-Firmen in den USA haben biochemische Verfahren entwickelt, die DNA-Stränge in der gewünschten Reihenfolge nach Auftrag zu synthetisieren. Die künstliche DNA, die durch die Polymerase-Kettenreaktion dupliziert wurde, enthielt die exakt gleichen Informationen. Die Speicherdichte ist enorm: Abschätzungen besagen, dass sich in einem Gramm DNA Milliarden von Gigabytes speichern lassen. In getrockneter Form sind die Moleküle sehr lange haltbar. Großer Nachteil: die Synthese der Kettenmoleküle ist heute zwar mit Labormitteln möglich, ist aber sehr zeitaufwendig und kostenintensiv. Die Automaten zum Auslesen der Informationen sind die gleichen, mit denen auch die menschlichen Gene entziffert werden, aber auch sie benötigen Zeit. Kommerziell verfügbare Sequenzier-Automaten können diese Reihenfolge der DNA-Bausteine wieder auslesen und in Zahlencode übersetzen. Die Startup-Firma CatalogDNA hat einen Automaten zur Synthese der Speicher-DNA entwickelt – noch hat er die Größe von einem Autobus. Auch Microsoft arbeitet zusammen mit der Universität von Washington an ähnlichen Projekten zur Datenspeicherung mit Biomolekülen.